THE PLATFORM
What 30 minutes with Talonic would tell you.
An honest walkthrough of the platform — every primitive, every tradeoff, every connector, with screenshots from the production product. Built for the engineer who's been asked to evaluate it by Friday.
Ingest once. Field registry. Map repeatedly.
Most document AI extracts into a single target schema — and stops. Talonic separates ingestion from output: documents are captured once into a reusable field registry, then mapped into schemas, cases, matching, and delivery as needs arise. No re-parsing.
- Ingest once. 25+ formats, 529-type ontology, multi-language classification. Every field resolves into a canonical registry that compounds across runs.
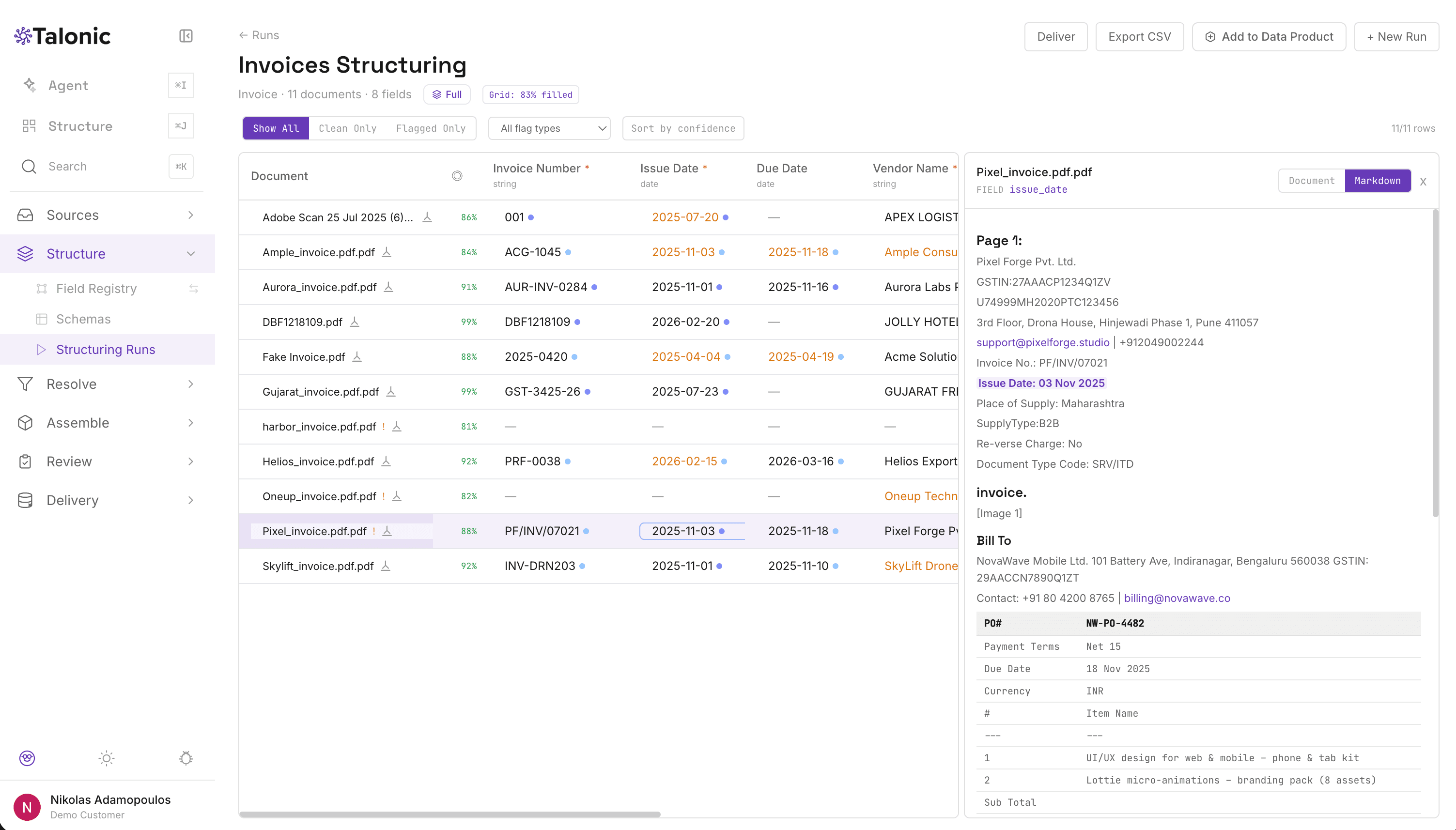
- Confidence-gated pipeline. Four extraction phases. Phase 1 fills ~30% of cells from the registry with zero AI calls. A 0.7 confidence gate protects values from being overwritten by later passes.
- Auditable per cell. Confidence, phase, reasoning trace, source reference. Click any value, see exactly how it got there — and where it ships.
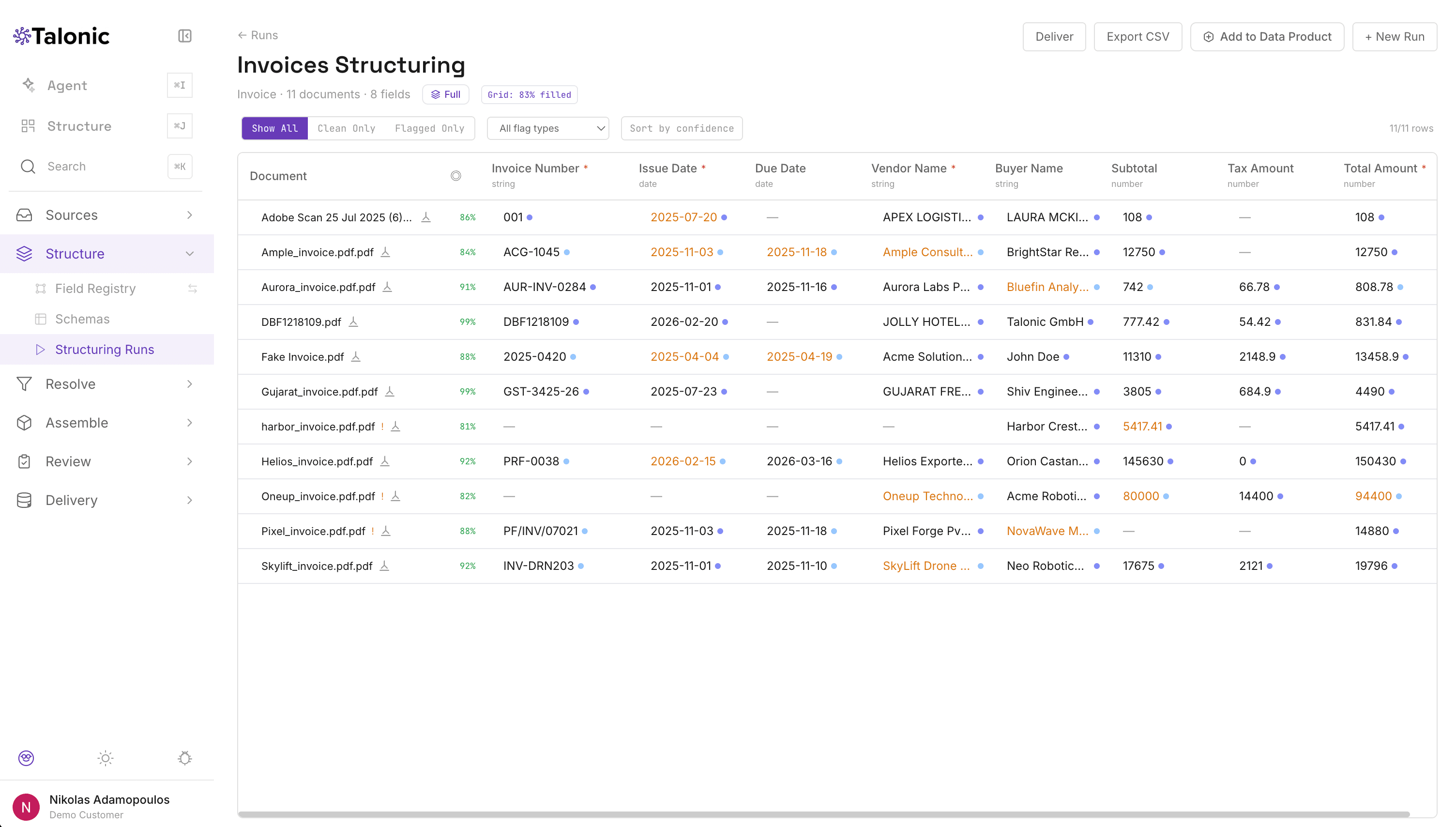
The extraction grid. Every cell carries confidence, phase, and a link back to the source.
01 SOURCES
Ingest anything.
Talonic accepts 25+ file formats through three processing paths. Plain-text formats — TXT, MD, HTML, XML, JSON, EML, CSV — are read directly with no external API calls. Image formats — PNG, JPG, GIF, WEBP — route to AI Vision for visual extraction. Document formats — PDF, DOCX, PPTX, XLSX, MSG, BMP — flow through the OCR pipeline and emerge as structured Markdown. ZIP archives unpack recursively; folder structure is preserved as a source_file_path field on every document inside. SHA-256 deduplication runs at upload, so the same file never enters the system twice.
Every document is classified automatically against a 529-type ontology. The classifier works across languages: a German Arbeitsvertrag and an English Employment Contract resolve to the same canonical type. Documents that don't match a known type land in Unclassified rather than failing — the registry expands when new types appear in production deployments.
No templates. No training data. No configuration. Upload, and the system already knows what the document is.
02 FIELD REGISTRY
A graph that compounds.
Every field discovered in every document resolves into a unified canonical registry. Fields organize into three tiers based on frequency. Tier 1 fields are core — universal across many document types, the most reliable. Tier 2 are established — promoted from Tier 3 after meeting frequency thresholds. Tier 3 are emerging — newly discovered, candidates for promotion as more data arrives.
Fields with similar meaning cluster automatically using AI embeddings. Vendor Name, Supplier Name, and Company Name resolve to the same canonical, with the source variants preserved as aliases. As the same field is extracted from many documents, AI synthesizes a master extraction instruction — a reusable directive that captures the best way to extract that field. Master instructions improve accuracy on every subsequent run.
The registry is the connective tissue between ingestion and delivery. Once a document, case, or record is structured into the Field Graph, it stays queryable across every schema evolution — indefinitely.
The registry doesn't just store fields. It earns them.
03 SCHEMAS
Output you control.
Schemas define the structure of your output. Two kinds exist. Generated schemas are produced automatically per document type from Tier 1 and Tier 2 registry fields. User templates are defined for specific output needs — a vendor contract template that targets your Ivalua schema, a logistics template that targets TMW.
Templates support a workshop system. Live is the current published version, read-only. Workshop is a mutable draft. Version History is the full timeline with diff summaries. Promoting a draft surfaces breaking changes — field removals, type changes — before they ship. A test extraction tool runs the draft against a sample of documents and shows draft-vs-live results side-by-side, so the impact of a schema change is visible before publish.
Every field supports format constraints (regex validation), modifiers (date and number formatting, value mapping, truncation), constraints (required, enum, length, cross-field expressions), bypass strategies (constant value, deterministic ID, reference-table lookup), and manual instructions that override the registry's master instruction.
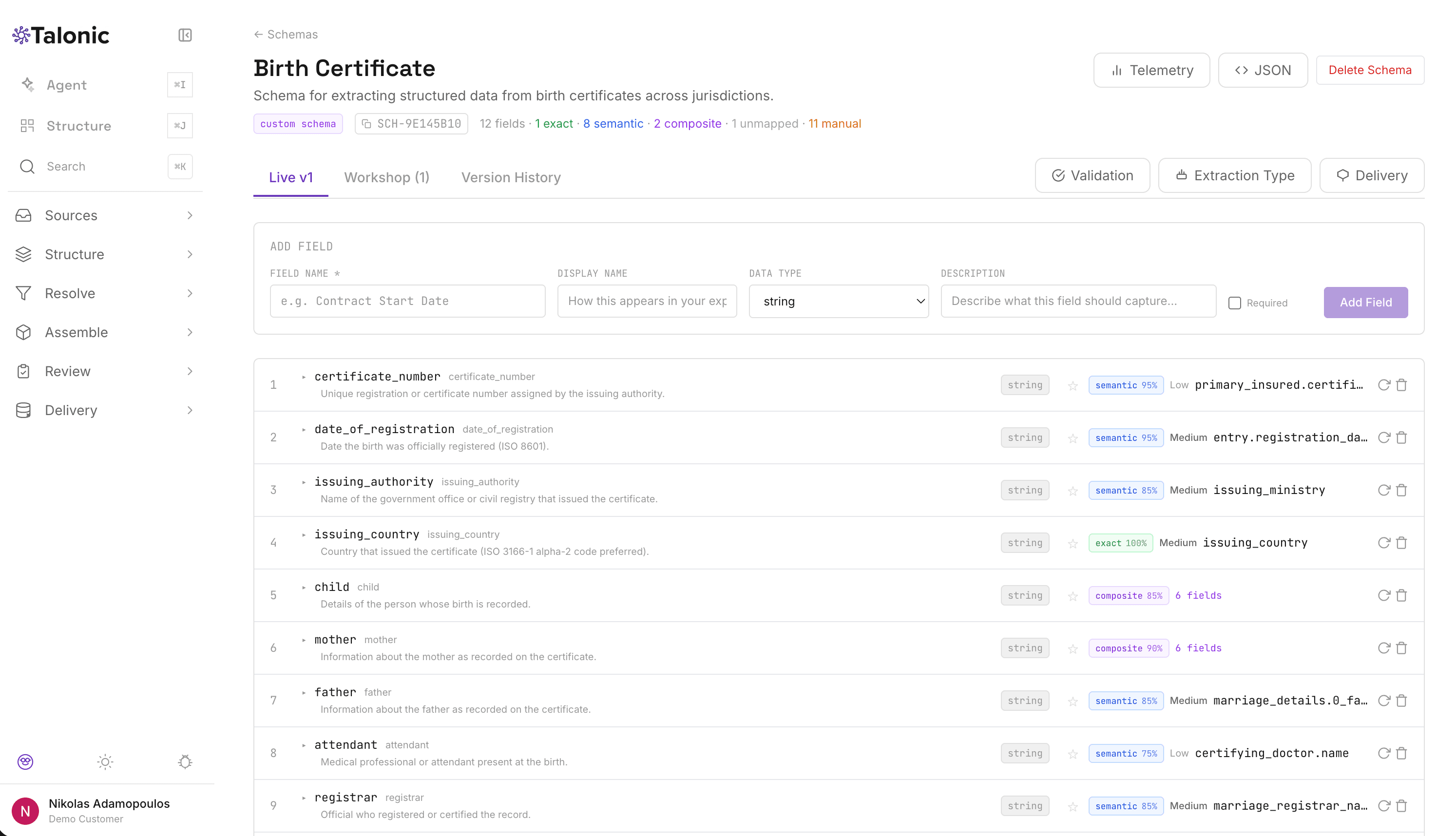
Every schema is a contract with your downstream systems. Talonic versions, diffs, and tests them like code.
04 PIPELINE
Four phases. One confidence gate.
Phase 1 fills 30% of cells from the registry — instant, no AI calls. Phase 2 reasons. Phase 3 validates. Phase 4 fills the gaps. Once a cell hits 0.7 confidence, no later phase can overwrite it. Every cell exposes its phase, confidence, and reasoning trace through the API — so agents and downstream systems can decide which values to trust on their own terms.
A job runs through four phases. Each phase fills more cells in the output grid. Earlier phases produce values that protect themselves from being overwritten by later, less-certain ones.
Phase 1 — Resolve. The fastest phase. ~30% of cells fill from existing graph matches with zero AI calls. Direct registry transfer, fuzzy name matching, concept-synonym expansion (supplier → vendor.company_name), reference-table lookups, description scans. Values are normalized at transfer: dates to YYYY/MM/DD, numbers to two decimal places, strings trimmed.
Phase 2 — Agent. An AI agent reviews the gap pattern in the grid and produces a typed strategy: compute (calculate from existing values via a safe expression evaluator, never eval()), transfer (copy from a semantically equivalent grid field), extract (re-read the source with specific instructions, batched at 5 concurrent), skip (with reasoning).
Phase 3 — Validation. Cross-field sanity checks. Date ordering, amount-vs-term consistency, lookup failures, low-confidence outliers, unexpected empty fields. Flags are informational only — they never block output, but they prioritize the review queue.
Phase 4 — Targeted Re-read. Context-aware gap filling. For each empty or low-confidence cell, the system re-reads the original document with the specific field instruction and the full grid as context. Often catches values missed in earlier phases.
The Confidence Gate. Once a cell is filled with confidence ≥ 0.7, no later phase can overwrite it. This is the rule that prevents a 0.95-confidence reference lookup in Phase 1 from being replaced by a 0.65-confidence agent extraction in Phase 4. The earliest reliable answer wins.
The earliest reliable answer wins. The latest hopeful guess loses. That's the gate.
05 VALIDATION
Quality gates, not after-the-fact reports.
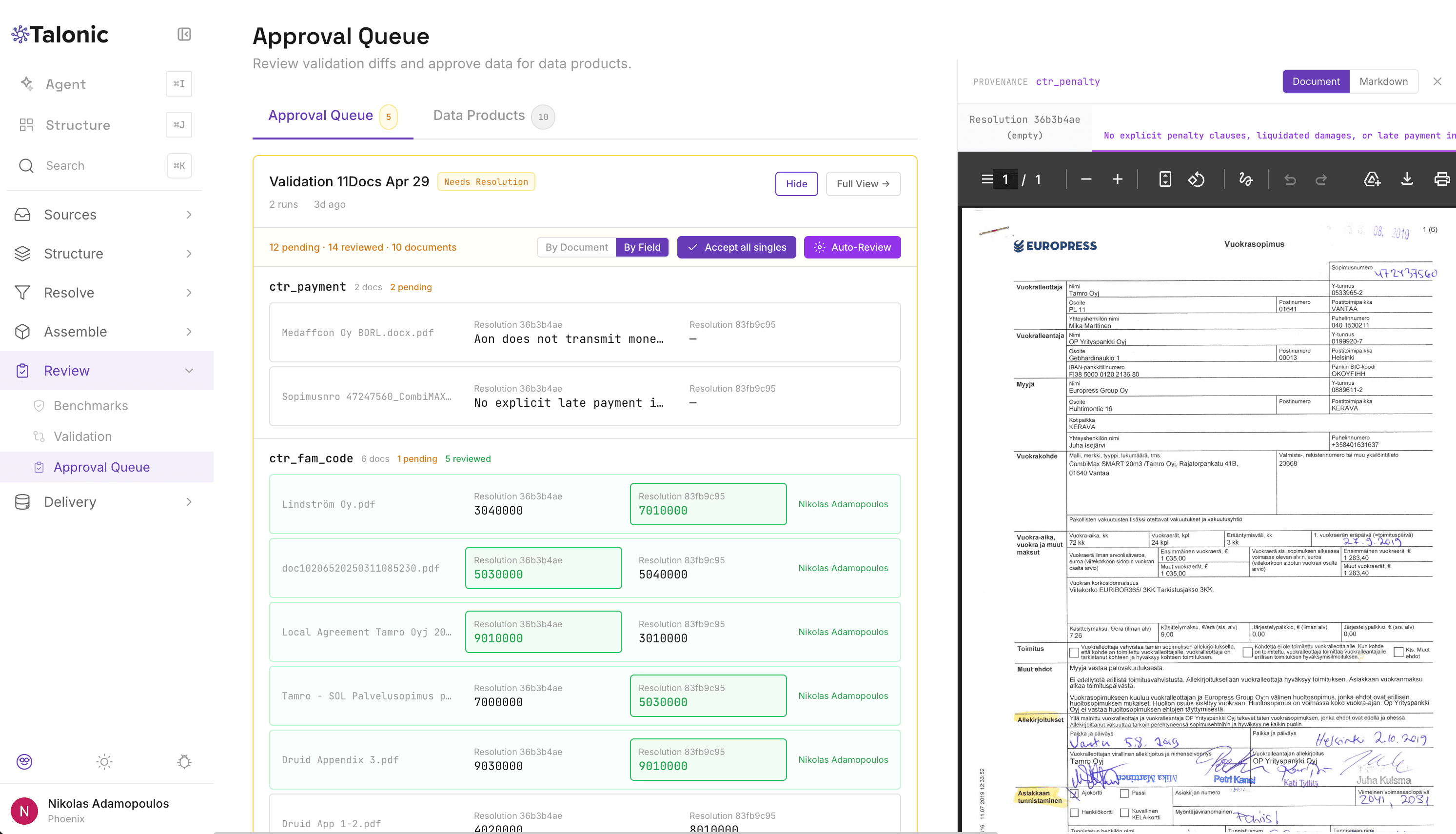
Schema-level validation rules run as part of every job. Rule types include field-format checks, value ranges, cross-field consistency, and AI-proposed coherence rules — proposed automatically after a job completes, then reviewed by a human before activation. Nothing AI-suggested ever goes live without explicit approval.
Golden samples — manually-created reference datasets with known-correct values — power benchmark runs. Every benchmark run compares extraction results against golden data per field, with an AI judge producing verdicts and a human able to override. This is how Bridgeway moved from 75% to 92% accuracy across POC cycles: each cycle's output became the next cycle's benchmark.
Approval gates are threshold-based rules that auto-approve or route to manual review. Configure per schema with criteria like minimum confidence, validation pass rate, and field coverage. Results meeting all thresholds auto-approve and trigger downstream delivery. Results that fail go to a human-in-the-loop review queue. The same result.approved signal fires on auto-approval and manual approval — your downstream systems don't know which path the record took.
06 CASES
Documents don't live alone.
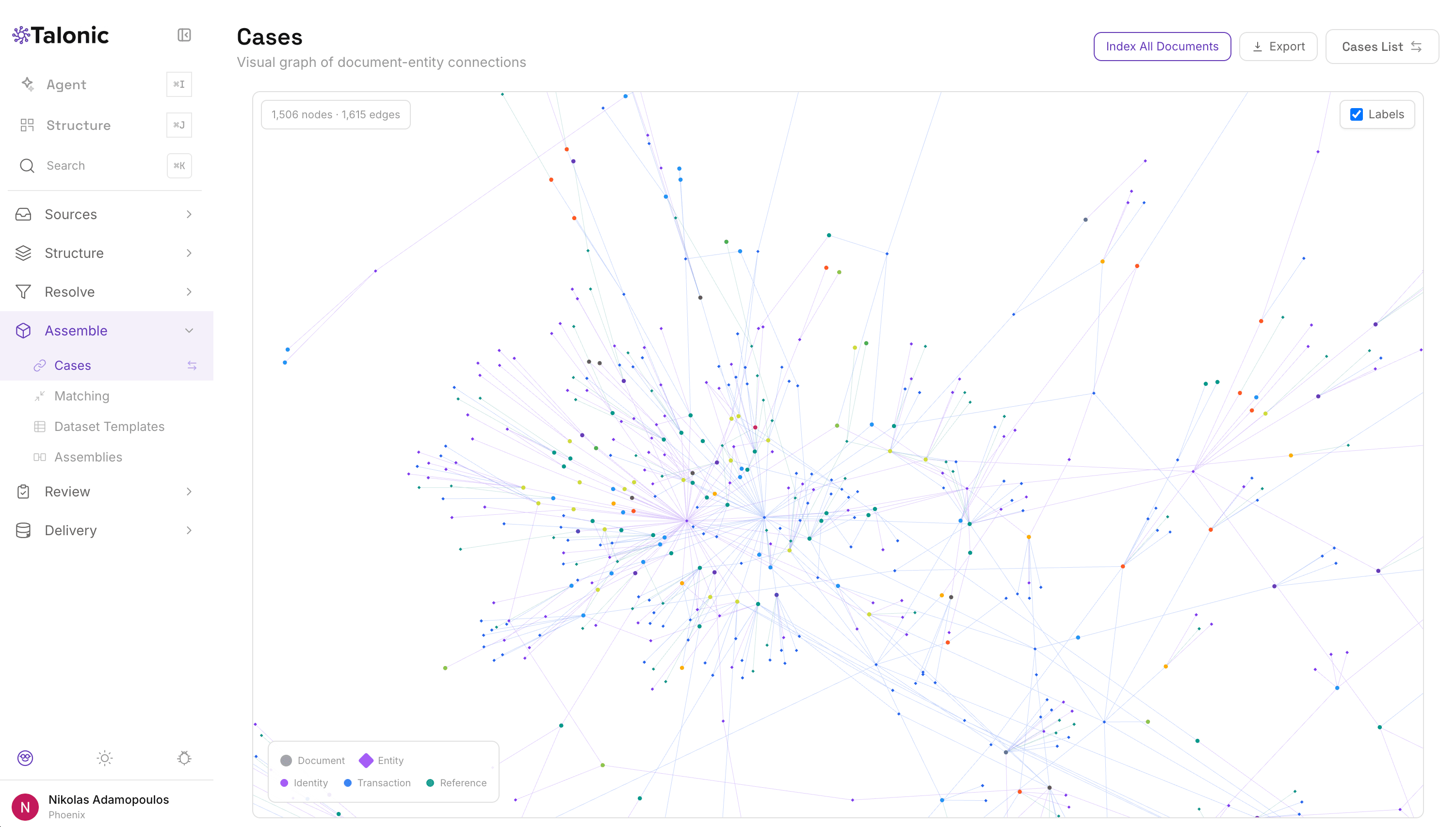
Identity, transaction, and reference keys link related documents into cases. The system finds them. You review them. The unit of work isn't the document — it's the case.
Most enterprise workflows don't run on individual documents — they run on bundles. A vendor onboarding is a contract plus a W-9 plus an insurance certificate plus a banking detail form. A logistics shipment is a bill of lading plus a customs declaration plus a packing list. A claims case is a policy plus an incident report plus three estimates.
Talonic identifies shared entities across documents — names, contract numbers, project codes, transaction references — and groups related documents into cases. Link keys are auto-classified as Identity (entity names), Transaction (numbers), or Reference (other shared IDs). High-frequency entities present in more than 30% of documents are excluded from case formation to avoid spurious links.
Each case shows the documents involved, the shared entities that connected them, the evidence chain (which fields produced which connections), a timeline, and an auto-generated AI narration of what the case appears to be. Case templates are auto-discovered after three or more cases form — the system identifies recurring document-type patterns.
The unit of work isn't the document. It's the case.
07 MATCHING
From extraction to reconciliation.
Extraction tells you what's in the document. Matching tells you what to do with it. Talonic supports field-to-field matching between extracted data and reference datasets — your carrier list, your vendor master, your chart of accounts.
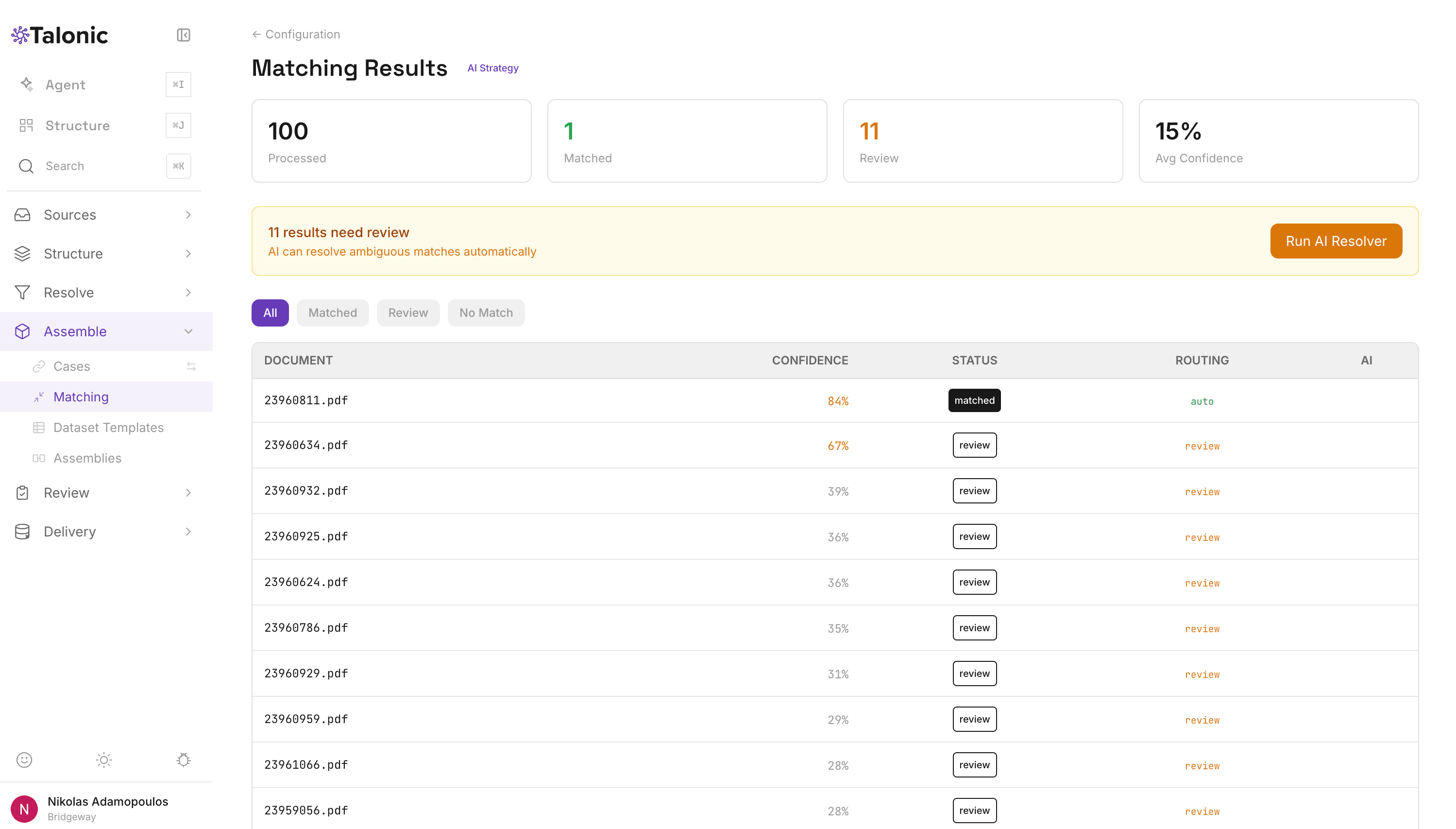
Four matching strategies combine into weighted scores. exact is case-insensitive string match. fuzzy is token-based similarity with configurable threshold. date_range matches dates within a configurable tolerance window. numeric_range matches numbers within a percentage or absolute tolerance. AI strategy generation can propose mappings automatically based on schema and reference structure.
Results show the top 5 candidates per document with field-level evidence — which strategies fired, what each contributed, where the score came from. A reference table with a properly loaded vendor list typically returns 90–100% accurate matches in a single run.
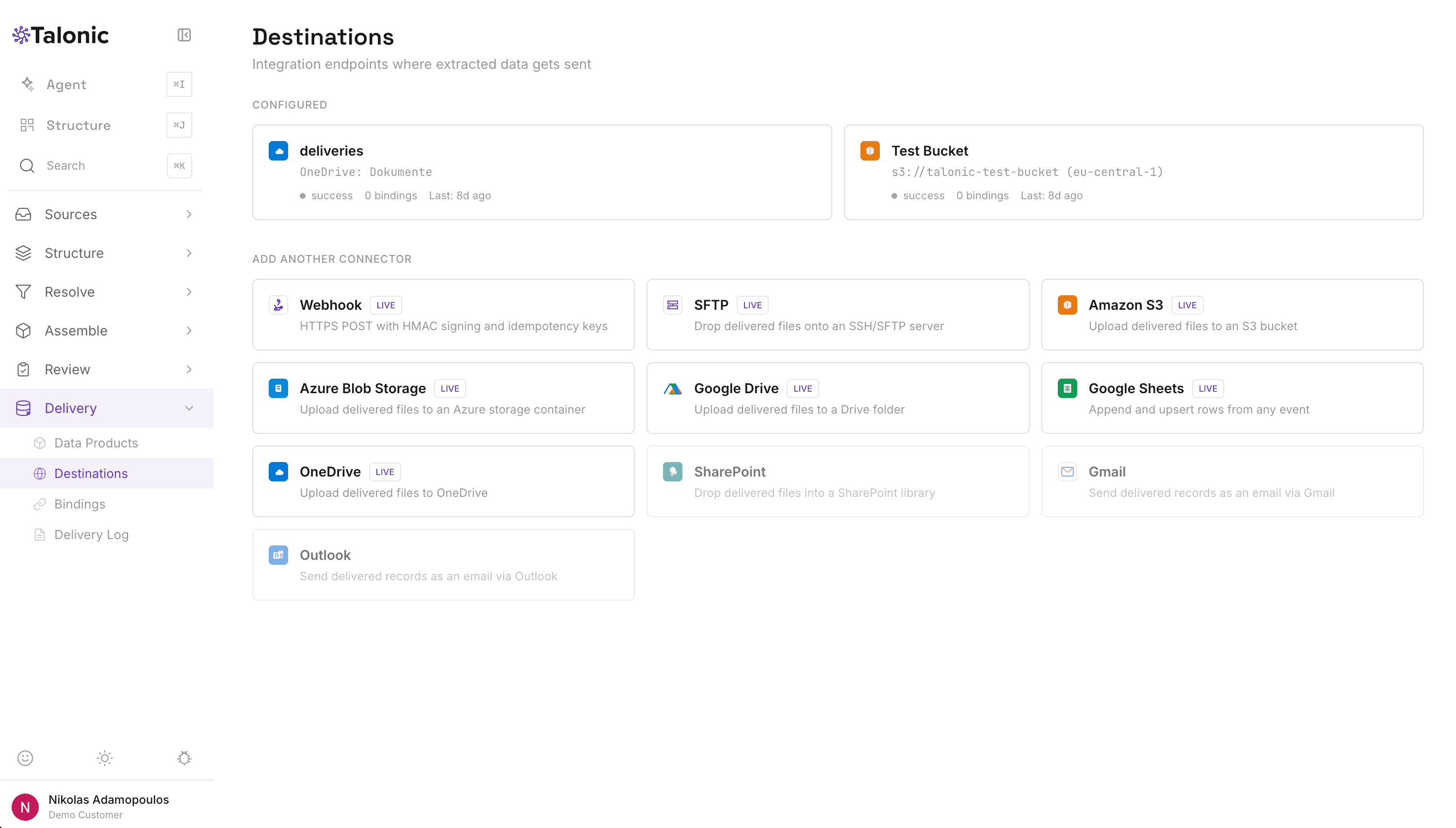
08 DELIVERY
Typed infrastructure, not a webhook.
Signal → Binding → Resolver → Serializer → Connector. Every attempt logged. Every failure replayable. Append-only history, idempotency keys on the wire, and a dead-letter queue you can drain. Deliver to your systems of record, your data warehouse, or directly into an agent's working memory — same typed pipeline, same signing, same replay.
Output flows through a five-stage delivery pipeline. Every stage is typed and observable.
Signal. A producer emits a typed event — document.extracted, result.approved, run.structuring.completed — into the outbox. Producers are stateless; they only publish.
Binding. A poller drains the outbox and matches each event against active bindings. A binding joins a signal filter to a deliverable type, a destination, and a serializer. The binding picker validates that all four pieces form a compatible triangle at create time, so misconfigurations fail loudly instead of silently.
Resolver. The deliverable resolver loads the actual payload — document metadata, a record snapshot, an extraction run — at delivery time, using only entity IDs from the signal. Stateless lookup at each delivery; no cached payloads going stale.
Serializer. Encodes the payload as json, ndjson, csv, csv_file, xlsx, rows, graph, raw, md, or txt. An optional field_map lets you rename fields, drop fields, or inject static values without writing code.
Connector. Ships the encoded bytes through the TransportWrapper — SSRF guard, payload cap, rate limit, retry ladder. Default ladder: six attempts at 5s, 30s, 2min, 10min, 1h. Slice-1 connector is webhook with HMAC-SHA256 signing, idempotency keys, and a 30-second timeout. S3, Google Sheets, Drive, SFTP, and Email arrive in subsequent slices.
Every attempt logs to delivery_items. Terminal failures escalate to delivery_dead_letter. Both are fully replayable; replay enqueues a fresh attempt with a new idempotency key. The history log is strictly append-only.
POST /v1/delivery/destinations
Authorization: Bearer $TALONIC_API_KEY
Content-Type: application/json
{
"type": "webhook",
"config": {
"url": "https://api.acme.com/talonic-events",
"timeout_ms": 30000,
"max_payload_bytes": 5242880
},
"credentials": {
"hmac_secret": "tlnc_hmac_..."
}
}
At-least-once delivery. Append-only history. Replayable everything. The webhook isn't the product. The pipeline behind it is.
09 API
Twenty namespaces. One auth header.
The platform exposes a typed REST API across twenty namespaces, designed for both production integrations and agent-driven access. Every primitive on this page has corresponding endpoints: /v1/extract for synchronous and asynchronous extraction, /v1/schemas for template management, /v1/jobs for run tracking and N-Shot comparisons, /v1/delivery for the full delivery surface, /v1/linking for the entity graph, /v1/cases for case management, /v1/matching for smart-matching configurations, /v1/quality for golden samples and benchmarks, and more.
API keys are prefixed tlnc_live_ (production) or tlnc_test_ (sandbox), passed as Authorization: Bearer, and SHA-256 hashed at rest — the full key is shown once at creation. Three scopes: extract (extraction API only), read (documents, extractions, schemas, jobs), write (create and modify resources). All list endpoints use cursor pagination. Idempotency-Key headers are honored on all write endpoints.
curl -X POST https://api.talonic.com/v1/extract \
-H "Authorization: Bearer $TALONIC_API_KEY" \
-F "file=@invoice.pdf" \
-F 'schema={"vendor_name":"string","total_amount":"number","due_date":"date"}'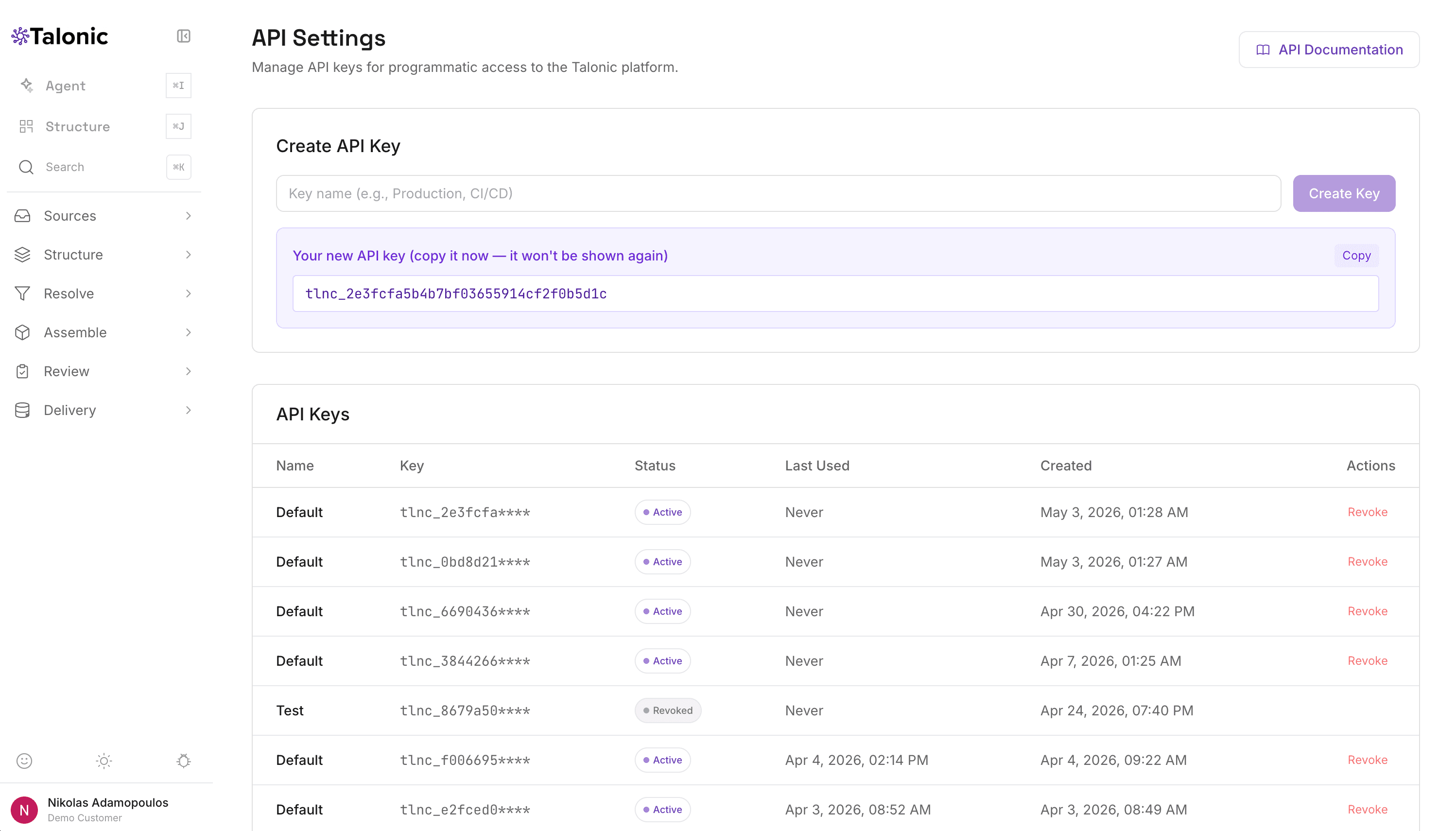
10 COMPARISON
What we are. What we aren't.
Every choice is a tradeoff. Here's what we'd tell you in person.
| Capability | Reducto | Instabase | General LLMs | Talonic |
|---|---|---|---|---|
| Data model | One target schema | One target schema | One prompt | Reusable field registry |
| Per-workflow cost | Re-parse every time | Re-parse every time | Re-prompt every time | Ingest once, map repeatedly |
| Output asset | One extraction payload | One extraction payload | Text completion | Compounding document data asset |
| Document parsing fidelity | Strong | Strong | Variable | Strong |
| Schema validation as primitive | Partial | Partial | None | Native |
| Case resolution / document graph | None | None | None | Native |
| Confidence gate / per-cell provenance | Partial | Partial | None | Native |
| Typed delivery pipeline (HMAC, DLQ, replay) | Partial | Partial | None | Native |
| EU data residency by default | Partial | Partial | Variable | Native |
| DIN SPEC 91491 alignment | None | None | None | Native |
We're slower out of the gate than parsing-first vendors and we're not always the cheapest per page. What you get for that is a system that compounds, audits, validates, and delivers — instead of one that returns text and stops.
If you want the fastest path from PDF to JSON with no concept of registry or compounding, Reducto is excellent. If you want the schema layer underneath your enterprise document workflow, that's us.
Two ways forward.
SCHEMA AUDIT
Send us a sample — a folder of contracts, a stack of scans, a case you can't resolve, a matching problem you've been hand-running in Excel. We'll return a schema read, an accuracy estimate, and a concrete recommendation within five business days.
Contact Sales →TECHNICAL DEEP-DIVE
For technical buyers in evaluation. 30 minutes with an implementation specialist or senior engineer. We'll answer specifics about architecture, throughput, residency, integration, and roadmap.
Read the docs →